이 글은 머신러닝 강의 과제인 분류 알고리즘을 사용한 예측모형들을 작성한 것으로, 개별 신청자 세부 정보, 재무 지표 및 대출 관련 요인을 기반으로 대출 승인 결과(loan_status)를 예측한다. 분류- 로지스틱 회귀분석, KNN,Tree,SVM,Ensemble(1.로지스틱 회귀분석+KNN+Tree+SVM, 2.Random frest, 3.Boosting)을 사용할 것이다.
사용 환경은 GoogleColab 환경을 사용하여 머신러닝 지도학습을 진행함.
1. 데이터 준비
import pandas as pd
import io
from google.colab import files
# 파일 업로드
uploaded = files.upload()
# 파일 읽기
df = pd.read_csv(io.BytesIO(uploaded['credit_risk_dataset(분류).csv']))
# 데이터프레임 확인
df.head()

2. 전처리 과정
credit_risk_dataset 데이터셋은 대출 신청자의 세부 정보와 재무 지표를 포함하여 나이, 연간 소득, 고용 기간, 신용도, 대출 금액, 이자율 등 대출 승인 여부에 중요한 변수를 담고 있다. 전처리 과정에서 결측치를 중앙값으로 대체하였는데, 이는 극단값에 덜 민감하여 변수의 대표성을 유지하는 데 유리했기 때문이다. 특히 loan_int_rate와 같은 변동성이 큰 변수에서 중앙값을 사용하여 데이터의 일관성을 높였다.
# 각 컬럼별 결측치 개수 확인
missing_values = df.isnull().sum()
# 결측치가 있는 컬럼과 그 개수를 출력
print(missing_values[missing_values > 0])
# 결측치가 포함된 행 수 확인
missing_rows = df.isnull().any(axis=1).sum()
print("결측치가 포함된 행 수:", missing_rows)
'''실행결과
person_emp_length 895
loan_int_rate 3116
dtype: int64
결측치가 포함된 행 수: 3943'''
# 중앙값으로 결측치를 대체
df = df.copy() # df를 복사하여 안전하게 작업
df['person_emp_length'] = df['person_emp_length'].fillna(df['person_emp_length'].median())
df['loan_int_rate'] = df['loan_int_rate'].fillna(df['loan_int_rate'].median())
# 결측치가 잘 제거되었는지 확인
missing_values_after = df.isnull().sum()
print("결측치 처리 후 남아있는 컬럼:")
print(missing_values_after[missing_values_after > 0])
'''실행 결과
결측치 처리 후 남아있는 컬럼:
Series([], dtype: int64)'''
이상치 처리는 person_age와 person_emp_length 변수에 적용했다. person_age는 18세에서 100세로, person_emp_length는 0년에서 50년으로 설정하여 비정상적인 값을 제거하였다. 이는 도메인 지식에 기반해 데이터의 신뢰성을 높이고 모델의 안정성을 확보하기 위함이다.
# 나이와 고용 기간의 합리적인 범위 설정
age_min, age_max = 18, 100 # 나이 범위
emp_length_max = 50 # 고용 기간 최대 값
# 나이와 고용 기간의 이상치 필터링
df = df[(df['person_age'] >= age_min) & (df['person_age'] <= age_max)]
df = df[df['person_emp_length'] <= emp_length_max]
# 처리 결과 확인
print("이상치 제거 후 데이터 크기:", df.shape)
'''이상치 제거 후 데이터 크기: (32574, 12)'''
범주형 변수인 cb_person_default_on_file은 원-핫 인코딩으로 변환하였고, 표준화를 통해 변수 간 크기 차이를 줄였다. 특히 KNN과 SVM과 같은 거리 기반 모델에서 표준화는 특정 변수가 과도하게 영향을 미치는 것을 방지하여 예측 성능을 개선하는 효과가 있다.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 독립 변수(X)와 종속 변수(y) 설정
X = df.drop(columns=['loan_status']) # 예측 대상 컬럼을 y 값으로 설정
y = df['loan_status'] # 종속 변수 설정
# 범주형 변수를 원-핫 인코딩으로 변환
X = pd.get_dummies(X, drop_first=True)
# 데이터 분할 (훈련 세트와 테스트 세트로 나누기)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 피처 스케일링 (표준화)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
또한, 클래스 비율이 크게 차이나는 문제를 해결하기 위해 Stratified K-Fold 교차 검증을 사용하여 각 폴드의 클래스 비율을 일정하게 유지하였다. 이를 통해 모델의 일반화 성능 평가의 신뢰성을 높였다. 이는 전처리 과정은 아니나 다른 대부분의 모델에 적용할 사항이라 앞에서 설명하고자 하였다.
3. 혼동행렬(Confusion Matrix)
혼동 행렬은 모델이 예측한 결과와 실제 값을 비교해 TP(참양성), TN(참음성), FP(거짓양성), FN(거짓음성)으로 구분하여 시각적으로 표현하는 방법이다. 이를 통해 정밀도, 재현율, F1 점수 등의 성능 지표를 세부적으로 분석할 수 있어 모델의 예측 오류 패턴을 구체적으로 파악하고 약점을 개선하는 데 유용하다.
| 구분 | 설명 |
| TP | 실제로 승인된 경우를 모델이 승인으로 정확히 예측한 경우 |
| TN | 실제로 비승인된 경우를 모델이 비승인으로 정확히 예측한 경우 |
| FP | 실제로 비승인된 경우를 모델이 잘못 승인으로 예측한 경우 |
| FN | 실제로 승인된 경우를 모델이 잘못 비승인으로 예측한 경우 |
true label은 데이터셋의 실제 값으로 모델이 예측해야 하는 정답 레이블을 의미하며, predicted label은 모델이 예측한 값으로 true label과 비교하여 모델의 정확도를 평가하는 기준이 된다. 혼동 행렬을 통해 모델이 어떤 유형의 오류를 더 자주 발생시키는지 확인함으로써 성능 개선에 필요한 부분을 구체적으로 파악할 수 있다.
4. 로지스틱 회귀분석
이번 포스트에서는 credit_risk_dataset를 기반으로 로지스틱 회귀모형을 활용한 대출 승인 예측 사례를 다룬다. 이 데이터셋은 개별 신청자의 세부 정보, 재무 지표, 대출 관련 요인들을 포함하며, 훈련 세트에서 약 86.67%, 테스트 세트에서 약 86.63%의 정확도를 보여준다. 이는 모델이 훈련 데이터에만 치우치지 않고 일반화 성능을 잘 유지하고 있음을 의미한다.
# 로지스틱 회귀 모델 학습 및 평가
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 로지스틱 회귀 모델 초기화
log_reg = LogisticRegression()
# 모델 학습
log_reg.fit(X_train_scaled, y_train)
# 훈련 세트와 테스트 세트 예측
y_train_pred_log = log_reg.predict(X_train_scaled)
y_test_pred_log = log_reg.predict(X_test_scaled)
# 훈련 세트 성능 평가
train_accuracy = accuracy_score(y_train, y_train_pred_log)
print("로지스틱 회귀 기본 모델 훈련 세트 성능:")
print(f"정확도: {train_accuracy:.4f}")
print(classification_report(y_train, y_train_pred_log))
# 테스트 세트 성능 평가
test_accuracy = accuracy_score(y_test, y_test_pred_log)
print("\n로지스틱 회귀 기본 모델 테스트 세트 성능:")
print(f"정확도: {test_accuracy:.4f}")
print(classification_report(y_test, y_test_pred_log))
'''로지스틱 회귀 기본 모델 훈련 세트 성능:
정확도: 0.8667
precision recall f1-score support
0 0.88 0.95 0.92 20368
1 0.77 0.55 0.65 5691
accuracy 0.87 26059
macro avg 0.83 0.75 0.78 26059
weighted avg 0.86 0.87 0.86 26059
로지스틱 회귀 기본 모델 테스트 세트 성능:
정확도: 0.8663
precision recall f1-score support
0 0.89 0.95 0.92 5099
1 0.76 0.56 0.64 1416
accuracy 0.87 6515
macro avg 0.82 0.75 0.78 6515
weighted avg 0.86 0.87 0.86 6515'''
모델의 성능을 최적화하기 위해 Stratified K-Fold 교차 검증(n_splits=5)을 사용해 각 폴드의 클래스 비율을 유지하면서 하이퍼파라미터 튜닝을 진행하였다. 주요 파라미터로는 C(정규화 강도), penalty(정규화 유형), solver(최적화 알고리즘)를 설정했으며, 그 결과 최적 조합으로 {'C': 0.1, 'penalty': 'l2', 'solver': 'liblinear'}가 도출되었다. 정밀도와 재현율에서는 약간의 변화가 있었지만, 과적합이나 과소적합 현상은 나타나지 않았다.
최적 값으로 재훈련시 성능 변화 는 다음과 같다.
훈련 세트 성능: 정확도: 0.8665, 정밀도: 0.7711, 재현율: 0.5530, F1-점수: 0.6441
테스트 세트 성능: 정확도: 0.8668, 정밀도: 0.7650, 재현율: 0.5586, F1-점수: 0.6457
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import StratifiedKFold, GridSearchCV
# Stratified K-Fold 교차 검증 설정
stratified_kfold = StratifiedKFold(n_splits=5)
# 로지스틱 회귀 하이퍼파라미터 설정
param_grid_logistic = {
'C': [0.01, 0.1, 1, 10, 100],
'penalty': ['l2'], # l1은 일부 solver에서 지원되지 않으므로 l2만 사용
'solver': ['liblinear', 'lbfgs']
}
# GridSearchCV를 통한 최적의 로지스틱 회귀 모델 찾기
grid_search_logistic = GridSearchCV(
LogisticRegression(),
param_grid_logistic,
cv=stratified_kfold, # Stratified K-Fold 적용
scoring='accuracy'
)
grid_search_logistic.fit(X_train_scaled, y_train)
# 최적 하이퍼파라미터와 검증 정확도 출력
print("로지스틱 회귀 최적 하이퍼파라미터:", grid_search_logistic.best_params_)
print("검증 정확도 (교차 검증 평균 정확도):", grid_search_logistic.best_score_)
'''로지스틱 회귀 최적 하이퍼파라미터: {'C': 0.1, 'penalty': 'l2', 'solver': 'liblinear'}
검증 정확도 (교차 검증 평균 정확도): 0.8661117495562918'''
혼동 행렬 분석 결과, TN과 TP가 높아 모델이 많은 샘플을 정확히 예측하고 있음을 알 수 있으며, FN이 상대적으로 많아 실제 긍정을 부정으로 예측하는 경향이 있다. 이는 모델의 약점을 개선하는 데 참고할 수 있는 부분이다.
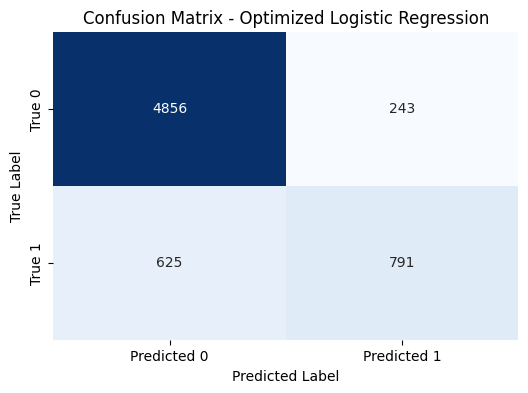
최종적으로, 하이퍼파라미터 최적화만으로는 성능 개선에 한계가 있어 추가적인 성능 향상을 위해 다른 모델을 탐색해보는 것도 좋은 접근이라는 결론에 이르렀다.
5. KNN - 최근접 이웃 분석
이번에는 K-최근접 이웃(KNN) 모델을 사용하여 대출 승인 예측을 수행한 사례를 다룬다. KNN 모델은 거리 기반 알고리즘으로, 새로운 데이터가 들어왔을 때 학습 데이터 중 가장 가까운 K개의 이웃을 참조하여 다수결로 예측을 수행한다. 이번 실험에서는 훈련 세트에서 약 91.80%, 테스트 세트에서 약 89.36%의 정확도를 보여, 훈련 데이터에 약간 치우치는 경향이 있으나 비교적 높은 예측 성능을 보였다.
# KNN 모델 학습 및 평가
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report
# 기본 KNN 모델 초기화
knn = KNeighborsClassifier()
# 모델 학습
knn.fit(X_train_scaled, y_train)
# 훈련 세트와 테스트 세트 예측
y_train_pred_knn = knn.predict(X_train_scaled)
y_test_pred_knn = knn.predict(X_test_scaled)
# 훈련 세트 성능 평가
train_accuracy = accuracy_score(y_train, y_train_pred_knn)
print("KNN 기본 모델 훈련 세트 성능:")
print(f"정확도: {train_accuracy:.4f}")
print(classification_report(y_train, y_train_pred_knn))
# 테스트 세트 성능 평가
test_accuracy = accuracy_score(y_test, y_test_pred_knn)
print("\nKNN 기본 모델 테스트 세트 성능:")
print(f"정확도: {test_accuracy:.4f}")
print(classification_report(y_test, y_test_pred_knn))
'''KNN 기본 모델 훈련 세트 성능:
정확도: 0.9180
precision recall f1-score support
0 0.92 0.98 0.95 20368
1 0.92 0.68 0.78 5691
accuracy 0.92 26059
macro avg 0.92 0.83 0.87 26059
weighted avg 0.92 0.92 0.91 26059
KNN 기본 모델 테스트 세트 성능:
정확도: 0.8936
precision recall f1-score support
0 0.90 0.97 0.93 5099
1 0.84 0.63 0.72 1416
accuracy 0.89 6515
macro avg 0.87 0.80 0.83 6515
weighted avg 0.89 0.89 0.89 6515'''
모델 성능을 최적화하기 위해 PCA를 사용하여 차원을 축소하고 Stratified K-Fold 교차 검증을 통해 하이퍼파라미터를 튜닝하였다. 주요 파라미터로는 주성분 개수(pca__n_components), 이웃 수(knn__n_neighbors), 가중치 방식(knn__weights), 거리 측정 방법(knn__metric)을 설정하였다. 최적의 조합은 {'knn__metric': 'manhattan', 'knn__n_neighbors': 15, 'knn__weights': 'distance', 'pca__n_components': 15}로 도출되었고, 이 설정을 통해 교차 검증 평균 정확도 89.86%, 테스트 세트 정확도 89.93%를 기록하였다.
from sklearn.decomposition import PCA
from sklearn.model_selection import StratifiedKFold, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score
# Stratified K-Fold 교차 검증 설정
stratified_kfold = StratifiedKFold(n_splits=5)
# PCA와 KNN을 파이프라인으로 연결
pipeline = Pipeline([
('pca', PCA()), # 주성분 개수는 GridSearchCV에서 최적화
('knn', KNeighborsClassifier())
])
# 하이퍼파라미터 그리드 설정 - KNN의 n_neighbors를 늘리고 PCA 주성분 개수 줄이기
param_grid = {
'pca__n_components': [5, 10, 15], # 주성분 개수 줄이기
'knn__n_neighbors': [10, 15, 20, 25], # 이웃 개수 늘리기
'knn__weights': ['uniform', 'distance'],
'knn__metric': ['euclidean', 'manhattan']
}
# GridSearchCV로 최적의 하이퍼파라미터 찾기
grid_search = GridSearchCV(
pipeline,
param_grid,
cv=stratified_kfold, # Stratified K-Fold를 적용하여 교차 검증
scoring='accuracy'
)
grid_search.fit(X_train_scaled, y_train)
# 최적 하이퍼파라미터와 검증 정확도 출력
print("최적 하이퍼파라미터:", grid_search.best_params_)
print("검증 정확도 (교차 검증 평균 정확도):", grid_search.best_score_)
# 최적 모델로 테스트 세트 성능 평가
best_model = grid_search.best_estimator_
y_test_pred = best_model.predict(X_test_scaled)
test_accuracy = accuracy_score(y_test, y_test_pred)
print("\n테스트 세트 정확도:", test_accuracy)
'''최적 하이퍼파라미터: {'knn__metric': 'manhattan', 'knn__n_neighbors': 15, 'knn__weights': 'distance', 'pca__n_components': 15}
검증 정확도 (교차 검증 평균 정확도): 0.8986145813220838
테스트 세트 정확도: 0.8993092862624712'''
재훈련 시 성능은 다음과 같다.
KNN 훈련 세트 성능: 정확도: 1.0000, 정밀도: 1.0000, 재현율: 1.0000, F1-점수: 1.0000
KNN 테스트 세트 성능: 정확도: 0.8993, 정밀도: 0.8777, 재현율: 0.6236, F1-점수: 0.7291
훈련 세트에서 모든 지표에서 100% 성능을 보였으나, 이는 KNN 모델이 훈련 데이터에 과적합되었음을 나타낸다. 차원 축소와 이웃 수 조정을 통해 과적합을 완화하고자 했으나, KNN 모델 특성상 훈련 데이터에 민감하게 반응하는 경향이 있다. 테스트 세트에서는 정확도 89.93%와 F1-점수 72.91%를 보여, 일정한 예측 성능을 유지했다.

혼동 행렬 분석 결과, TN과 TP 값이 높아 모델이 많은 샘플을 정확히 예측하고 있음을 알 수 있으며, FN이 상대적으로 많아 실제 긍정을 부정으로 예측하는 경향이 있음을 확인했다.
'머신러닝' 카테고리의 다른 글
| 파이썬과 케라스를 이용한 간단한 딥러닝 + (1) | 2024.11.28 |
|---|---|
| 지도학습 - 주택 가격 회귀 예측모형 / 전처리 + 회귀모형 + KNN (0) | 2024.11.25 |
| 지도학습 - 대출 승인 결과 분류 예측모형 / 앙상블 (1) | 2024.11.23 |
| 지도학습 - 대출 승인 결과 분류 예측모형 / Tree,SVM (0) | 2024.11.14 |



